Enterprise Prompt Engineering at Scale: Standards, Testing, and the Production Prompt Lifecycle
Enterprise Prompt Engineering at Scale: Standards, Testing, and the Production Prompt Lifecycle
May 15, 2026
Most enterprise AI programmes have prompt engineering. Very few have enterprise prompt engineering. The difference is not the quality of individual prompts. It is the absence of a discipline: a defined structure that every production prompt must follow, a testing standard that every prompt must pass before deployment, a performance measurement framework that tells you whether the prompt is still working six months after launch, and a lifecycle that governs every prompt from first draft to eventual retirement.
Individual prompting is a skill. Enterprise prompt engineering is a discipline. Skills are individual and context-dependent. Disciplines are reproducible, transferable, and measurable. The enterprise AI programme that treats its prompt work as a skill -- collecting clever prompts from skilled individuals and making them available in a shared folder -- has not yet built the foundation for the 4x speed with quality benchmark that Phase 5 of enterprise AI transformation requires.
This article covers the practitioner side of enterprise prompt engineering: how a prompt should be structured, how it should be tested, what metrics prove it is performing, and the seven anti-patterns that consistently destroy enterprise prompt programmes before they compound into genuine competitive advantage.
The companion article -- Industrialising Prompts: How SMB Tactics Scale into Enterprise AI Architecture -- covers WHY you need a governed prompt library and the five maturity levels. This article covers HOW to fill it correctly.'
Section 1 - Why Enterprise Prompt Engineering Is a Different Discipline
Individual prompting optimises for the individual's output quality. Enterprise prompt engineering optimises for reproducible, governed, measurable output quality across a user population whose AI literacy, domain expertise, and task context vary significantly. The prompt that a senior legal partner writes for a specific contract review task will be excellent for that partner and useless for a junior associate who does not know enough about contract law to recognise when the output is subtly wrong.
Enterprise prompt engineering solves this by embedding the domain expertise in the prompt architecture itself -- so that a junior associate using a properly structured enterprise prompt produces output that reflects the senior partner's knowledge, not just their own. That is the leverage that individual prompting cannot create, and that enterprise prompt engineering exists to produce.
The Four Dimensions That Separate Enterprise From Individual Prompting
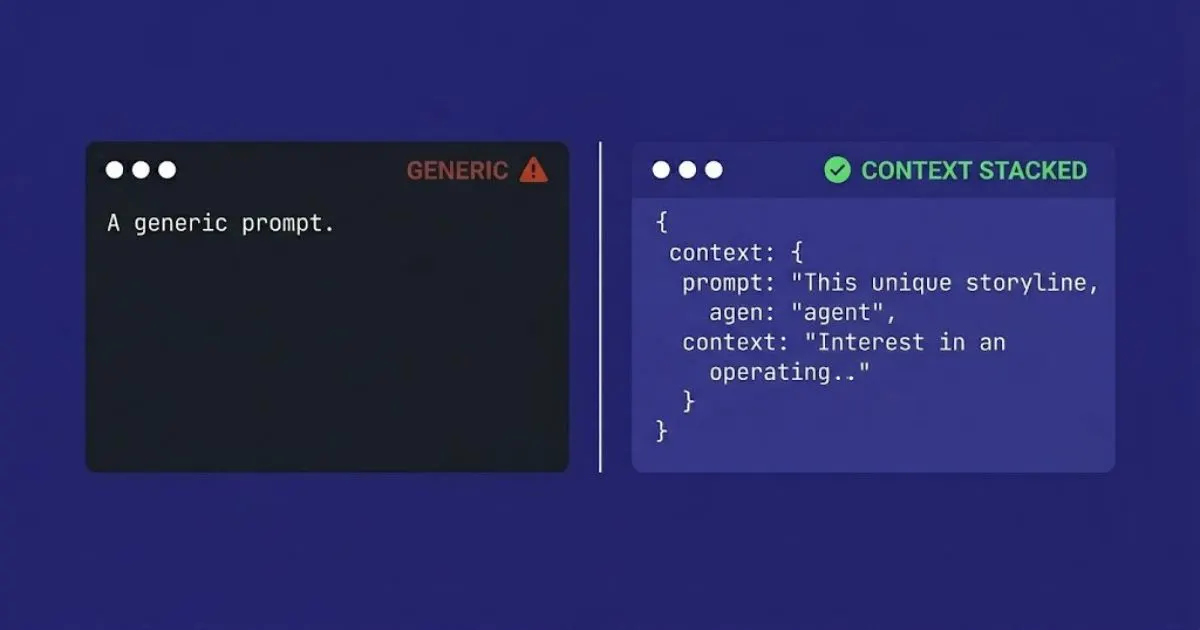
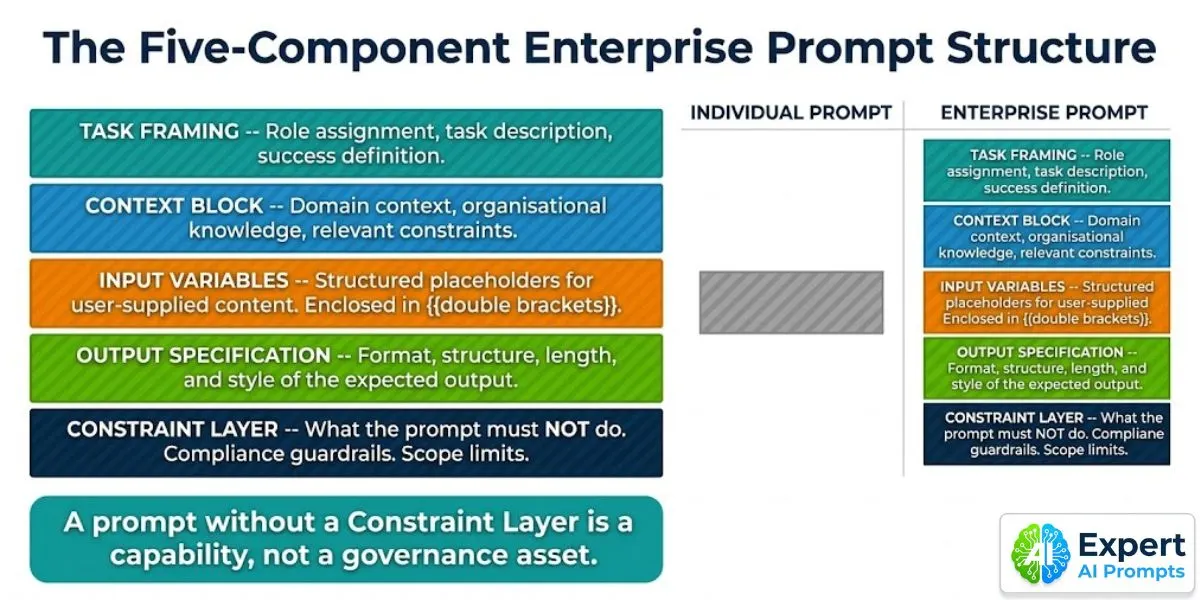
• STRUCTURE: Individual prompts typically have one component -- a task description. Enterprise prompts require five: task framing, context block, input variables, output specification, and constraint layer. The structure is the standard. Prompts that do not meet the standard are not admitted to the library.
• TESTING: Individual prompts are tested by the person who wrote them, with a sample of their own work. Enterprise prompts are tested against a representative dataset of not fewer than 25 inputs, reviewed by a domain expert, and measured against a defined accuracy standard before production deployment.
• MEASUREMENT: Individual prompts are never measured in production -- the user knows intuitively whether they are working. Enterprise prompts are measured continuously: quality metrics, efficiency metrics, adoption metrics, and business impact metrics. Drift is detected and remediated.
• GOVERNANCE: Individual prompts are owned by the person who wrote them and disappear when that person leaves. Enterprise prompts are version-controlled, access-governed, categorised, owned by the CoE, and archived on retirement. They are organisational assets, not personal tools.
Section 2 - The Five-Component Enterprise Prompt Structure
Every production prompt in an enterprise prompt library must have all five components documented. The component structure is the engineering standard, not a formatting suggestion. Prompts that do not meet the standard are returned to draft.
Component 1: Task Framing
What it is: The opening component that tells the model who it is and what it is doing. Includes role assignment (the expertise context the model should apply), a precise task description (what must be produced, not how to produce it), and a success definition (what a good output looks like, at a level of specificity that a model can self-evaluate against).
Why it matters at scale: Role assignment calibrates the model's output register to the expertise level required by the enterprise context. A legal contract review prompt without role assignment produces outputs at a generalised competence level. With role assignment ('You are a senior commercial contracts lawyer reviewing this agreement for a company with operations in Australia, UK, and EU jurisdictions'), it produces outputs calibrated to the specific expertise level the organisation needs.
Component 2: Context Block
What it is: The domain-specific knowledge, organisational context, and background information that the model needs to produce outputs that are useful in the organisation's specific context rather than generically. The context block is what makes an enterprise prompt domain-specific rather than generic.
Why it matters at scale: The context block is where organisational intelligence is encoded in the prompt. A customer service prompt for a telecommunications company's enterprise team has a different context block than the same task for a retail bank. The context block contains the organisation-specific knowledge that junior users would not know to provide without it, and that distinguishes the enterprise prompt from anything available off-the-shelf.
Component 3: Input Variables
What it is: Structured placeholder fields for the user-supplied content that varies from task to task. Enclosed in {{double brackets}} or a consistent delimiter system, labelled clearly with the type of content expected (e.g., {{CONTRACT_TEXT}}, {{JURISDICTION}}, {{CLIENT_CONTEXT}}). Variables are the mechanism by which a prompt is made reusable across different task instances.
Why it matters at scale: A prompt without defined input variables requires the user to know exactly how to structure their input to get a good output. A prompt with clearly labelled variables guides even low-AI-literacy users to provide the right input in the right format. The variable structure is also what enables prompt automation -- workflow systems can populate variables programmatically rather than requiring user input for routine tasks.
Component 4: Output Specification
What it is: A precise specification of the expected output format, structure, length, and style. Not 'write a summary' but 'produce a structured summary in the following format: [Section 1: Key Issues -- 3-5 bullet points] [Section 2: Recommended Actions -- numbered list] [Section 3: Risk Level -- single sentence]. Maximum 300 words.'
Why it matters at scale: Inconsistent output format is the primary cause of revision cycles in enterprise AI programmes. When the output format is precisely specified, downstream processes that consume AI outputs -- review workflows, document management systems, handoff procedures -- can be designed against a consistent format. The output specification is what enables AI outputs to be consumed programmatically by workflow automation systems.
Component 5: Constraint Layer -- The Governance Component
What it is: An explicit list of what the prompt must NOT do: topics it must not address, claims it must not make, client information it must not disclose, regulatory statements it is not qualified to produce, scope boundaries it must not cross. The constraint layer is the governance component of the prompt -- and the component that most individual prompts entirely lack.
Why it matters at scale: A prompt deployed without a constraint layer at enterprise scale will, eventually, produce an output that no one intended and everyone regrets. The constraint layer is not a limitation on the prompt's capability -- it is the boundary that makes the capability trustworthy enough to deploy at scale. Every regulated use case, customer-facing application, and legally sensitive workflow requires an explicit constraint layer before production deployment.
A prompt without a Constraint Layer is a capability, not a governance asset. Do not deploy it to a user population of more than five people without one.
Enterprise AI Governance Framework
The Constraint Layer requirements for regulated and high-risk AI use cases are defined in the Enterprise AI Governance Framework.'
Section 3 - The Six-Stage Production Prompt Lifecycle
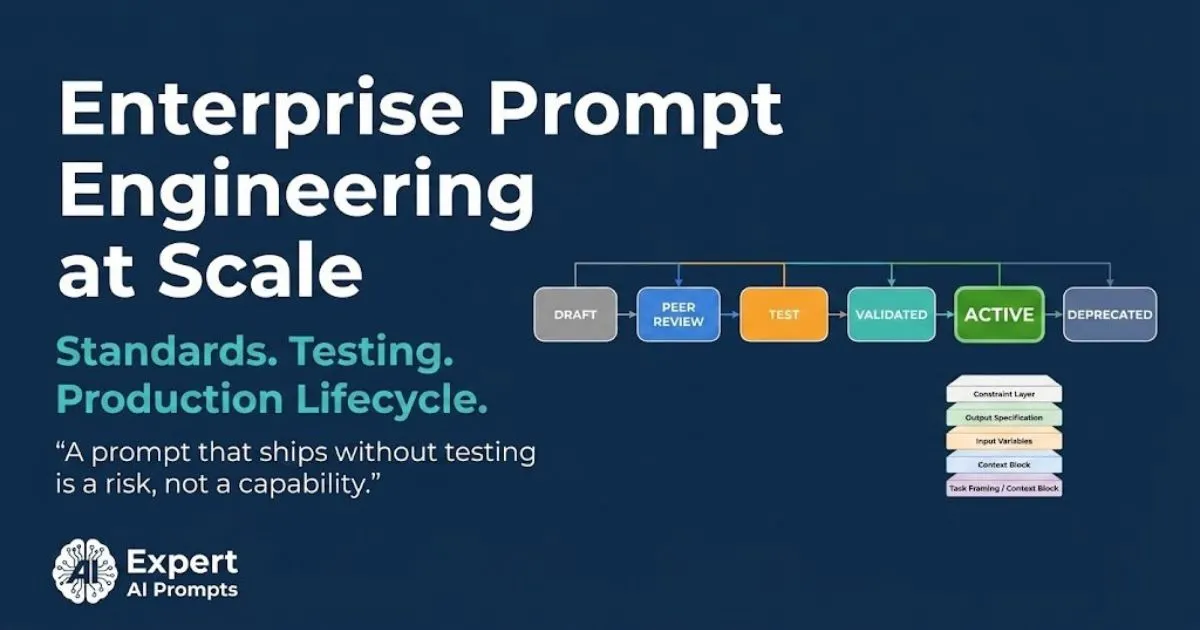
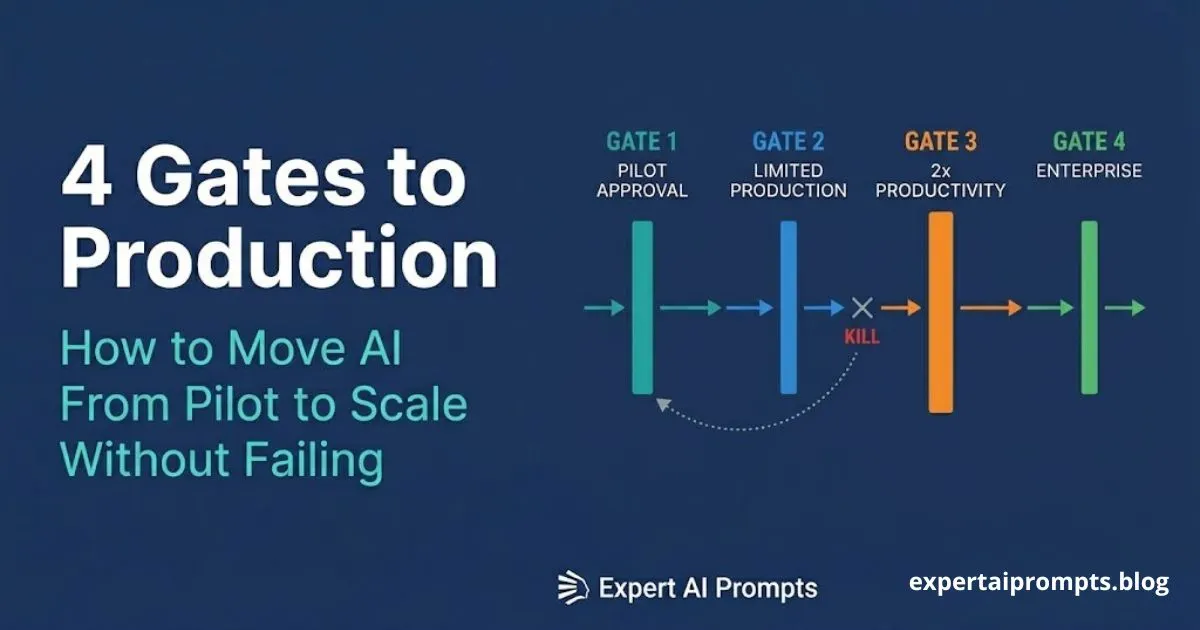
A prompt that ships without a defined lifecycle is not a production asset. It is a draft that accidentally reached production. The six-stage lifecycle applies to every prompt in an enterprise prompt library, without exception.
Stage 1: Draft
The prompt author writes the initial version using the five-component structure template. Draft status means: not reviewed, not tested, not available to users. Draft prompts are stored in the working library section, visible to the prompt engineering team and the relevant domain lead, but not to the general user population.
Stage 2: Peer Review
Two reviewers: a domain expert (is this accurate and appropriate for the domain?) and a prompt engineer (does this meet the five-component structure standard?). Both must approve. Prompts that fail domain review are returned to draft with specific feedback. Prompts that fail structure review are returned to draft with the missing components identified.
Stage 3: Test -- The Gate Most Organisations Skip
The tested prompt is run against a test dataset of not fewer than 25 representative inputs. The test dataset covers: typical use cases (80% of the dataset), edge cases that could plausibly arise in normal operation (15%), and adversarial inputs that attempt to bypass the constraint layer (5%). Results are reviewed by the domain expert. An accuracy score is calculated against the defined success criteria. Prompts that do not meet the minimum accuracy threshold are returned to draft for revision.
Stage 4: Validated
The prompt has passed testing with a documented accuracy score at or above the minimum threshold (typically 90% for regulated use cases, 85% for operational use cases, 80% for informational use cases). Validated status is recorded with: the accuracy score achieved, the test dataset used, the date of validation, and the names of the reviewers who approved. This documentation is the governance audit trail for the prompt.
Stage 5: Active
The prompt is published to the production library, accessible to the authorised user population, with its category, use case description, and input variable guide documented. Performance monitoring begins at this point: the prompt's outputs are sampled periodically (typically 10% of production uses), evaluated against the quality metrics, and compared to the validated baseline.
Stage 6: Deprecated / Archived
When a prompt is superseded by a better version, when a model update changes its behaviour significantly, or when the use case it serves is no longer relevant, the prompt moves to Deprecated status. Deprecated prompts are removed from the active library but archived permanently -- they are retained for audit, version history, and the institutional knowledge they represent. They are never deleted.
The production lifecycle is the mechanism that moves prompt work past the pilot stage -- the same discipline that separates the 14% who reach production from the 78% who do not.
Section 4 - Prompt Testing at Scale: How to Know a Prompt Is Production-Ready
Most enterprise AI programmes deploy prompts the way software was deployed before automated testing became standard practice: write it, show it to a few people, decide it looks good, ship it. The result is the equivalent of code that crashes in production under conditions that the developer never thought to test.
Enterprise prompt testing is not difficult -- but it requires the same discipline as any quality assurance process: a defined test dataset, a defined success criterion, a defined review process, and a recorded result. The prompt that cannot pass this standard is not production-ready, regardless of how impressive it looks in a demo.
The Minimum Testing Standard for an Enterprise Production Prompt
1. DEFINE THE SUCCESS CRITERION before testing begins. 'The output is useful' is not a success criterion. 'The output correctly identifies all material clauses requiring review, with no false negatives and fewer than 5% false positives, at a reading level appropriate for the junior associate user' is a success criterion.
2. BUILD THE TEST DATASET from real work, not from hypothetical examples. A test dataset for a contract review prompt should contain 25 actual contracts (anonymised if necessary) that represent the full range of document types, jurisdictions, and complexity levels the prompt will encounter in production.
3. INCLUDE ADVERSARIAL INPUTS -- inputs designed to test the constraint layer. For a customer communication prompt, adversarial inputs might include requests to disclose confidential pricing, provide regulatory advice, or comment on pending litigation. These inputs should produce outputs that correctly apply the constraint layer. Prompts that fail adversarial testing are not production-ready, regardless of their performance on typical inputs.
4. REQUIRE TWO INDEPENDENT REVIEWERS for the test results. The prompt author should not be one of them. The domain expert reviews for accuracy; the prompt engineer reviews for structural compliance and constraint layer integrity.
5. DOCUMENT THE TEST RESULT in the prompt record: accuracy score, test dataset used, date, reviewers, and any specific failure modes identified. This documentation is the governance evidence for the prompt's production approval.
Section 5 - Prompt Performance Metrics: Measuring What Matters
A prompt in an enterprise prompt library that is not measured in production is not a managed asset -- it is an untended deployment. Prompt performance degrades over time as the model it runs on is updated, as the domain context it was calibrated to evolves, and as users find ways to use it outside its intended scope. Measurement is what detects degradation before it produces consequential errors.
Enterprise prompt performance is measured across four metric categories:
Quality metrics: Accuracy rate against the expected output standard (sampled from production use, reviewed by domain expert). Human evaluator agreement score (how consistently human reviewers agree that the output is correct). Domain expert approval rate (percentage of sampled outputs that the domain expert approves without revision). For regulated use cases, a compliance review rate is added: percentage of outputs that satisfy the applicable compliance standard.
Efficiency metrics: Time-to-useful-output vs the pre-AI baseline for the same task. Revision cycle reduction: how many rounds of editing does the AI output require before it is used, compared to the pre-AI baseline. Task completion rate without manual intervention: what percentage of uses produce an output that is directly used without revision.
Adoption metrics: Active use rate: what percentage of the authorised user population uses the prompt at least once per week. Champion Network utilisation: what percentage of Champion-led training sessions result in sustained adoption (measured at 30 days). Repeat use rate: what percentage of first-time users return to use the prompt again.
Business impact metrics: Time saved per task category (hours per week across the user population). Error rate reduction compared to pre-AI baseline for the same task type. Output quality score against the pre-AI baseline as assessed by domain experts. These are the metrics that justify the enterprise prompt programme's continued investment at board level.
The 4x speed with quality benchmark is the Phase 5 target: 4x faster than the pre-AI baseline with output quality maintained or improved. Measure against this benchmark for every active prompt in the library. Prompts that have not approached this target within 90 days of production deployment should be reviewed for revision or replacement.
Enterprise AI Transformation Playbook
The 4x speed with quality benchmark is the Phase 5 target in the Enterprise AI Transformation Playbook. Prompt performance measurement is how you demonstrate Phase 5 progress.
Section 6 - The Prompt Engineering Operating Model
Enterprise prompt engineering does not happen as a side activity of people who also do other things. It requires a defined operating model: clear roles, defined responsibilities, a governance owner, and a production pipeline. The organisations that treat prompt engineering as an informal community activity consistently produce prompt libraries that start well and degrade over time as the informal community moves on to other priorities.
Roles: From Prompt Author to Prompt Product Manager
Prompt Author: Subject matter experts from each business function. Domain knowledge is the primary qualification; prompt engineering skills are developed through the five-component structure training. Prompt Authors draft prompts for their domain, participate in peer review, and provide ongoing domain validation as the library evolves.
Prompt Engineer: Technical specialist responsible for structure compliance, testing protocol execution, and constraint layer design. The Prompt Engineer is not primarily a domain expert -- they are a quality assurance function for the prompt library. In early-stage enterprise AI programmes, this role may be held by the CoE lead rather than a dedicated specialist.
Prompt Product Manager: Responsible for the performance and strategic direction of the prompt library as a whole. Prioritises which new prompts are developed, monitors performance metrics across the library, identifies prompts that need revision, and owns the roadmap for the prompt programme. In mature enterprise AI programmes, this is a dedicated role. In earlier-stage programmes, it is typically held by the CAIO or the CoE lead.
CoE Governance Owner: The AI Centre of Excellence owns the prompt library as an organisational asset. It sets the structure standard, approves the testing protocol, authorises production deployment, and governs access control and retirement. Without a clear governance owner, the prompt library does not compound -- it accumulates drift.
The AI Centre of Excellence is the governance owner of the enterprise prompt programme. The CoE structure that makes this operating model sustainable is covered in the AI Centre of Excellence guide.
Section 7 - Prompt Drift: The Silent Performance Degrader
Prompt drift is the progressive degradation of a prompt's output quality over time, without any change to the prompt itself. It occurs through three mechanisms: model updates that change the model's underlying behaviour in ways that the prompt's calibration no longer matches; domain context drift where the organisational context or regulatory environment the prompt was calibrated to has evolved; and usage scope creep where users apply the prompt to task types it was not designed for.
Prompt drift is the primary reason that enterprise prompt programmes that do not have continuous performance monitoring consistently underperform. A prompt that was excellent at validated accuracy of 92% in January may be operating at 74% accuracy in June, because the model it runs on has been updated three times since validation. Without measurement, this degradation is invisible until it produces a consequential error.
The detection protocol for prompt drift: sample 10% of all production uses monthly and review against the quality metrics. Compare the sampled accuracy score to the validated baseline. A drop of more than 8 percentage points from the validated baseline triggers a prompt review. The review determines whether the degradation is caused by model update (solution: re-test against the current model version and revise if needed), domain drift (solution: update the context block to reflect current context), or usage scope creep (solution: update the constraint layer and user guidance).
Section 8 - The Seven Enterprise Prompt Anti-Patterns
These seven patterns consistently destroy enterprise prompt programmes before they compound into genuine advantage. Each is common enough that one of them is present in virtually every enterprise AI programme that is not yet producing business-level results.
1. THE PROMPT DUMP: Collecting every prompt anyone has ever used into a shared folder, labelling it a 'library', and declaring the enterprise prompt programme complete. A prompt dump is not a library. A library has structure, governance, quality standards, and a lifecycle. A dump has none of these and produces no compounding value.
2. VALIDATION BY DEMO: Testing a prompt by showing it working well in a demonstration scenario, rather than against a representative dataset. Demo inputs are chosen to show the prompt performing well. Representative datasets contain the edge cases and adversarial inputs that the demo never encounters. Every prompt looks good in a demo. Not every prompt performs at production.
3. THE ORPHANED CONSTRAINT LAYER: Adding compliance constraints to prompts as an afterthought, after a near-miss in production, rather than as a structural requirement from the first draft. By the time a constraint layer is retrofitted, the prompt has already been in production long enough to have produced outputs that should not exist.
4. PROMPT HOARDING BY FUNCTION: Business functions treating their prompts as proprietary assets that should not be shared with other functions. Domain-specific content should be maintained by each function; structural patterns and techniques should be shared across the library. Prompt hoarding prevents cross-functional learning and produces redundant, inconsistent implementations of the same task type.
5. MEASURING ADOPTION INSTEAD OF PERFORMANCE: Reporting the number of users with access to the prompt library as the success metric, rather than the quality and business impact of the outputs it produces. Adoption metrics tell you that people have access. Performance metrics tell you whether the access is producing value. Deloitte 2026 found fewer than 60% of employees with approved AI tools use them regularly -- adoption is a floor, not a ceiling.
6. IGNORING DRIFT UNTIL FAILURE: Running no performance monitoring on active prompts, operating on the assumption that a prompt validated six months ago is still performing at its validated accuracy level. Model updates happen monthly. Domain contexts change. Prompts that are not monitored degrade silently and fail consequentially.
7. LETTING THE PROMPT LIBRARY BECOME THE CAIO'S PERSONAL PROJECT: Prompt library development owned exclusively by the CAIO or a small central team, without meaningful contribution from domain experts in each business function. The result is a library of technically well-structured prompts that do not reflect actual domain knowledge, and adoption by the user population never reaches the level needed for genuine business impact.
Closing - From Prompt to Organisational Asset
Enterprise prompt engineering is the discipline that converts a collection of clever inputs into an organisational knowledge asset that compounds over time. The five-component structure gives every prompt the architecture it needs to be useful across a diverse user population. The six-stage production lifecycle gives every prompt the quality assurance it needs to be trusted at scale. The performance measurement framework gives every prompt the continuous monitoring it needs to remain valuable as models and contexts evolve.
The enterprise AI programme that masters this discipline produces something that individual prompting cannot: a governed prompt library that gets more accurate, more domain-specific, and more valuable with every prompt added, every performance review completed, and every revision made. That is the compounding mechanism that produces the 4x speed with quality benchmark. Not a better model. Not a larger technology budget. A better discipline.
Your next steps:
The companion article: why you need a governed prompt library and the five maturity levels.
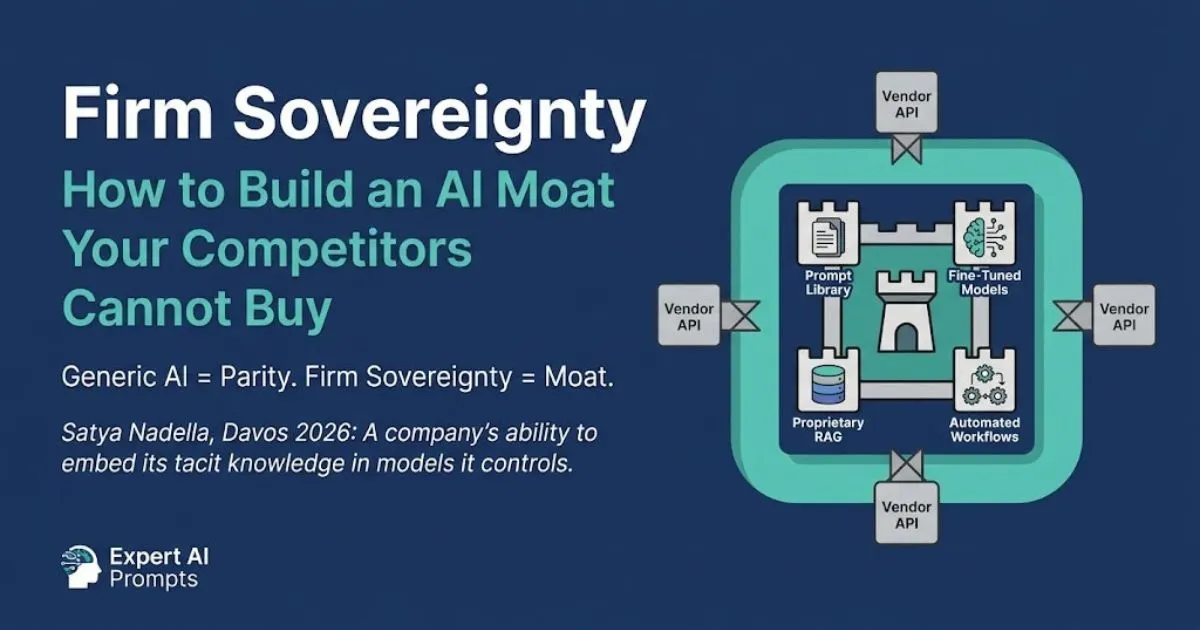
Firm Sovereignty: Building an AI Moat
The governed prompt library is the primary Firm Sovereignty asset. The full architecture of what compounds after Level 5 is in Firm Sovereignty.
Enterprise AI Transformation Playbook
Phase 5 (4x speed with quality) is the enterprise prompt programme's north star. The full five-phase framework is in the Playbook.
About the Author
Matthew Bulat is the Founder of Expert AI Prompts and a 20+ year technology and AI strategy executive. Former CTO, Federal Government Technical Operations Manager for national infrastructure across 20 cities and 4,000 users, and 8+ year University Lecturer at CQUniversity. Expert AI Prompts -- 30 industries, 1,500+ domain-specific prompts, 15 AI workflow systems -- is the live proof-of-concept of the enterprise prompt engineering discipline described in this article.